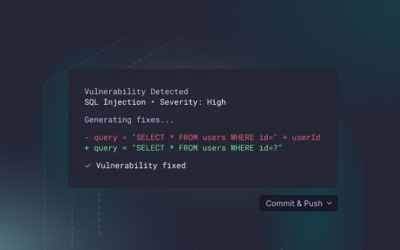
When it comes to testing APIs, no single approach covers everything. Unit tests verify expected behavior. Integration tests check that services communicate correctly. But what about the inputs nobody planned for, the malformed JSON payloads, the oversized strings, the unexpected data types that real-world traffic inevitably sends? That is where API fuzz testing fills the gap.
Fuzz testing sends large volumes of randomized, malformed, or unexpected data to your API endpoints and watches what happens. The goal is not just to confirm that things work when used correctly. It is to find out what breaks when they are not. For security engineers and developers building API-driven applications, fuzzing is one of the most effective ways to identify potential vulnerabilities before attackers do.
What Is API Fuzz Testing?
API fuzz testing is an automated software testing technique where an API fuzzer generates and sends random data, malformed inputs, and boundary-value test cases to your API endpoints. Instead of checking whether your API returns the correct response for valid inputs, fuzz testing checks how your API handles the unexpected.
The testing process typically works like this:
- Define the target API endpoints using API specifications like an OpenAPI Specification or Swagger file.
- Generate inputs automatically. An API fuzzer creates thousands of mutated requests, altering data types, injecting special characters, sending oversized payloads, or omitting required fields.
- Send the requests to the running API and monitor every response.
- Analyze the results for anomalies: crashes, 500-series status codes, unusual latency, stack traces in error messages, or unexpected behavior that signals a vulnerability.
What makes fuzzing different from traditional testing methods is its focus on the unknown. Manual testing and unit testing rely on test cases that a developer writes based on known scenarios. Fuzzing generates inputs that go beyond what any developer would think to test, targeting edge cases and corner cases that can hide serious security vulnerabilities.
For example, a typical test might confirm that a POST /users endpoint creates a user when given valid JSON. A fuzz test asks harder questions. What happens when the name field contains 10,000 characters? What if the email field receives an integer instead of a string? What if the request body is encoded in an unexpected format? These are the conditions where buffer overflows, injection attacks, and data exposure tend to occur.
StackHawk’s runtime application security testing takes a similar philosophy, testing against live applications with real requests and analyzing actual responses, not just static code. This approach catches vulnerabilities that only appear when an API is actually running and processing traffic.
Why API Fuzzing Catches What Other Tests Miss
Traditional testing methods have a fundamental limitation: they verify what you already know should work. Static analysis reads source code but does not execute it. Unit testing confirms expected behavior for expected inputs. Even penetration testing, while valuable, is constrained by the time and scope a human tester can cover in an engagement.
API fuzzing fills a different role in the testing process. It explores the space of inputs that nobody anticipated.
Fuzzing uncovers edge cases at scale. A manual tester might try a handful of malformed requests against an endpoint. An API fuzzer generates thousands of randomized inputs per minute, systematically testing boundary conditions, unexpected data types, and malformed payloads that would take a human months to attempt. This matters especially for large APIs with dozens or hundreds of endpoints, each accepting multiple parameters.
Fuzzing reveals deeper logic flaws. Some vulnerabilities only surface when specific combinations of inputs interact with backend logic in unexpected ways. Stateful fuzz testing, where the fuzzer learns API request dependencies and chains them together, can expose authorization issues and business logic flaws that single-request testing rarely reaches.
Fuzzing finds unknown vulnerabilities. Unlike signature-based security scanners that check for known exploit patterns, fuzzing does not depend on a database of known threats. This makes it effective at uncovering zero-day vulnerabilities and issues unique to your specific API implementation.
This is particularly relevant for organizations that want thorough coverage. Fuzzing can surface many of the issues in the OWASP API Security Top 10, including injection flaws, broken authentication, and mass assignment. But it also catches vulnerabilities that fall outside documented categories entirely, the implementation-specific edge cases that no predefined checklist covers.
Common Vulnerabilities API Fuzzing Uncovers
API fuzz testing is especially effective at surfacing security issues that other testing approaches regularly miss. Here are the most common API vulnerabilities that fuzzing reveals:
Injection attacks. When an API does not properly sanitize inputs, fuzz testing can trigger SQL injection, NoSQL injection, and command injection. The fuzzer sends special characters, escape sequences, and malicious payloads across every parameter. These are among the most dangerous common API vulnerabilities because they can give attackers direct access to backend systems, whether that means databases, operating system commands, or internal services.
Buffer overflows and memory errors. Sending unexpectedly large payloads or deeply nested data structures can expose memory handling flaws, particularly in APIs built with lower-level languages. Fuzzing systematically pushes beyond boundary limits that manual testing rarely reaches.
Authentication and authorization issues. A fuzzer that chains stateful requests can test whether expired tokens still grant access or whether modifying user IDs in request parameters leads to unauthorized data exposure. It also checks whether role-based access controls hold up under malformed inputs.
Error handling and sensitive data leaks. When APIs encounter unexpected data, poor error handling often leaks internal details. Fuzz testing regularly catches APIs returning stack traces, database schema information, or internal file paths in error messages. These details give attackers a blueprint for deeper exploitation.
Rate limiting weaknesses. The high volume of requests that fuzzing generates can also reveal whether your API properly enforces rate limits. If an API fails to throttle malformed traffic, it may be vulnerable to denial-of-service through uncontrolled resource consumption.
Input validation failures. APIs that rely on client-side validation without server-side enforcement are prime targets. Fuzzing bypasses any front-end checks entirely, sending raw requests that expose how your API actually handles unexpected data at the server level.
Understanding which vulnerabilities fuzzing targets helps you identify issues early in the development process. StackHawk’s runtime testing covers many of these same vulnerability categories during active security scans, including SQL injection, cross-site scripting, and broken authentication. It’s Business Logic Testing capability extends coverage to multi-user authorization and workflow-level flaws. Together, this complements and extends your fuzzing efforts.
API Fuzz Testing Techniques
Not all fuzzing approaches work the same way. Choosing the right technique depends on your API’s complexity, the depth of testing you need, and what you already know about your API’s schema.
Mutation-Based Fuzzing
This approach starts with valid inputs and systematically alters them. A mutation-based fuzzer takes a working API request and changes individual fields: flipping bits, replacing strings with special characters, swapping data types, or truncating values. It is fast to set up because it does not require deep knowledge of the API specification. The tradeoff is that mutations may not reach deeply into application logic if the starting inputs are too simple.
Generation-Based Fuzzing
Generation-based fuzzers build inputs from scratch using knowledge of the API’s schema. If you provide an OpenAPI specification, the fuzzer creates requests that are structurally aware of your API’s expected parameters, data types, and constraints, then systematically violates those constraints. This produces more targeted test cases that explore the structured invalid space just outside normal operation. Generation-based fuzzing can often reach more semantically meaningful code paths than mutation-based approaches because it uses knowledge of the API schema to guide test generation.
Schema-Aware Fuzzing
A step beyond basic generation, schema-aware fuzzing uses your API’s schema as a map. It knows which fields are required, what data types each accepts, what the valid ranges are, and what relationships exist between parameters. This lets it generate inputs that are “just wrong enough” to be interesting. A required field that is present but contains the wrong type. An integer field set to the maximum value plus one. A string field filled with SQL metacharacters. Tools like Schemathesis treat this as property-based testing informed by OpenAPI or GraphQL schemas.
Stateful REST API Fuzzing
Many APIs require sequences of calls to function correctly. You cannot test an order checkout endpoint without first creating a cart and adding items. Stateful fuzzers learn these dependencies using API specifications to infer relationships between requests, then build request sequences that mirror realistic workflows while fuzzing parameters at each step. Microsoft’s RESTler is the most well-known example, automatically learning producer-consumer relationships between endpoints and generating chained test sequences.
| Technique | Best For | Input Source | Setup Effort |
| Mutation-based | Quick broad coverage | Existing valid requests | Low |
| Generation-based | Schema-aware exploration | API specifications | Medium |
| Schema-aware | Targeted boundary testing | OpenAPI/Swagger specs | Medium |
| Stateful | Multi-step workflow testing | API spec + learned dependencies | High |
For most teams, combining techniques provides the best coverage. Start with schema-aware fuzzing for breadth, then add stateful fuzzing for your most critical API flows, especially those involving authentication, payment processing, or sensitive data handling.
How to Add API Fuzzing to Your Development Process
The biggest shift in modern API security testing is moving fuzzing from a periodic, manual exercise into a continuous testing practice embedded in your CI/CD pipeline.
Use Your API Specifications to Drive Testing
If your APIs are documented with an OpenAPI specification or similar format, that specification becomes the foundation for your fuzzing efforts. It tells the fuzzer what endpoints exist, what parameters each accepts, and what data types are expected. Teams that maintain accurate API specs get significantly better fuzzing results because the fuzzer can generate inputs that are semantically meaningful rather than purely random.
For teams that do not have complete API documentation, StackHawk’s API Discovery can analyze connected repositories to identify testable APIs and, where supported, generate OpenAPI specifications to accelerate testing.
Embed Fuzzing in CI/CD
Running fuzz tests manually once a quarter does not keep pace with modern development. Effective API fuzzing runs automatically on every pull request or at a minimum on every merge to the main branch. This makes fuzzing part of the development process rather than a separate security exercise that happens after the fact.
Most modern fuzzing tools integrate with CI/CD pipelines. Configure your fuzzer to run in a staging or pre-production environment that mirrors production, targeting the endpoints most likely to handle sensitive data or user input first. When fuzzing reveals a vulnerability, it should surface directly in the developer’s workflow through the same channels they already use for build failures and test results.
Prioritize Your Endpoints
Not every API endpoint carries the same risk. Focus your fuzzing efforts on:
- Endpoints that handle authentication and authorization
- Endpoints that accept file formats or complex input structures
- Endpoints that interact with databases or external services
- Endpoints that process payment or personally identifiable sensitive data
- Any endpoint exposed to the public internet
Analyze Results and Reduce False Alarms
Raw fuzzing output can be noisy. A 500 status code might indicate a real vulnerability or just a missing input validation message. Effective teams build a triage process: categorize findings by severity, verify that flagged issues are reproducible, and prioritize fixes based on actual security risk rather than volume.
Modern DAST tools like StackHawk help here by providing actionable findings with precise request/response evidence, reproduction steps, and remediation guidance. This reduces the time developers spend sorting through results and makes it faster to identify issues that actually matter.
Why Fuzzing Matters More in the Age of AI-Generated Code
AI-assisted development has introduced new security risks that many organizations are not yet equipped to handle. When developers use AI coding assistants to generate API endpoints, middleware, and business logic, the volume of code being shipped increases dramatically. But the amount of testing applied to that code has not kept pace.
AI-generated code introduces specific fuzzing-relevant risks:
More code, more untested surface area. AI tools generate functional code quickly, but the code they produce often handles happy-path scenarios while leaving edge cases, error handling, and input validation incomplete. These are exactly the kinds of gaps that fuzz testing is designed to catch.
Unfamiliar code paths. When developers write code themselves, they have mental models of how it should behave. AI-generated code bypasses that understanding. A developer might not know every assumption the AI made about input validation or error handling. Fuzzing provides a safety net by exercising the code without assumptions about its internal behavior.
Inherited vulnerability patterns. AI models trained on large code corpora can reproduce common vulnerability patterns like improper input sanitization or missing authorization checks. Fuzzing these endpoints systematically is one of the most efficient ways to catch security risks that were baked in during generation.
For a deeper look at how the industry is responding to AI-era application security challenges, StackHawk’s 2026 AI Era AppSec Survival Guide covers the latest survey data and strategies.
Complementing Fuzzing with DAST for Full API Security
Fuzz testing is powerful, but it is one piece of a complete API security strategy. Fuzzing can surface known vulnerability patterns, such as injection flaws, and it excels at discovering unexpected input-handling behavior. But it is most effective when paired with structured testing for business logic flaws and architectural security issues.
This is where combining fuzzing with dynamic application security testing produces the strongest results. DAST tools test running applications with active security checks and attack patterns to uncover exploitable vulnerabilities in real execution paths, catching common API vulnerabilities like SQL injection, cross-site scripting, and broken access control. Fuzzing adds a randomized, exploratory testing layer that can uncover robustness and input-handling issues beyond the deterministic checks most DAST workflows emphasize.
Together, the combination covers both the known and the unknown:
| What It Tests | Fuzzing | DAST |
| Unknown input validation flaws | Yes | Limited |
| Known vulnerability patterns (OWASP Top 10) | Partial | Yes |
| Business logic flaws | With stateful fuzzing | Yes |
| Authentication/authorization | With stateful fuzzing | Yes |
| Performance under malformed input | Yes | No |
| CI/CD integration | Varies by tool | Yes (StackHawk runs natively in CI/CD) |
For teams already running DAST, adding fuzzing extends coverage into territory that traditional testing methods cannot reach. For teams starting from scratch, pairing API fuzzing with a runtime testing platform like StackHawk can improve coverage while keeping security testing closer to developer workflows.
StackHawk’s platform is built around this idea. It’s runtime application security testing runs deterministic, reproducible scans that catch known vulnerabilities, while its API Discovery feature ensures you are testing every endpoint in your attack surface, not just the ones you know about. For teams building applications that incorporate LLMs directly, StackHawk also offers LLM application security testing that covers risks like prompt injection, sensitive data disclosure, and improper output handling.
Getting Started with API Fuzz Testing
API fuzz testing is not an optional nice-to-have. As APIs grow in complexity and AI-generated code increases the surface area that needs testing, fuzzing becomes one of the most reliable ways to uncover potential vulnerabilities before they reach production.
The path forward is clear. Start with your most critical API endpoints. Use your API specifications to guide the fuzzer. Embed testing into your CI/CD pipeline, and combine fuzzing with DAST to cover both known and unknown risks. The result is a more secure API that your team can ship with confidence.
If you want to see how StackHawk helps security engineers and developers test APIs comprehensively, from discovering your full API attack surface to running runtime security scans in every PR, sign up for a free trial or schedule a demo to see the platform in action.