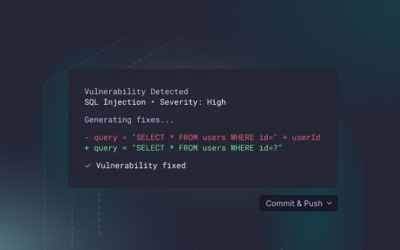
OpenAI’s Codex Security scanned 1.2 million commits during its private beta and surfaced over 10,000 high-severity findings. Those numbers got the attention of every security-conscious engineering team, including ours. The more interesting question isn’t whether an AI agent can identify vulnerabilities in source code. It clearly can. The question we keep coming back to at StackHawk is whether finding those issues in source code is enough to secure a running system.
Our view is that it isn’t. Codex Security is a real step forward for developers who want to catch issues earlier, and we’re glad OpenAI built it. It is also, by design, a repository- and code-centric system, and entire categories of vulnerabilities are only observable or confirmable at runtime. Most of the launch coverage glossed over that distinction. We don’t think it should be glossed over because we see the consequences of it regularly in customer environments.
This post covers what Codex Security actually does, where it genuinely helps, and where runtime testing still has to do the work.
What Is Codex Security?
Codex Security is OpenAI’s application security agent, launched in March 2026 as a research preview for ChatGPT Pro, Enterprise, Business, and Edu customers. It evolved from Aardvark, OpenAI’s agentic security researcher announced in October 2025, and is currently accessed through the Codex web interface via ChatGPT, where it connects to repositories and runs analysis in isolated environments using OpenAI’s frontier models.
What’s notable is the ordering. Conventional SAST workflows begin with rules, taint tracking, or dataflow analysis. Codex Security starts from repository context and threat modeling, then attempts to validate findings before surfacing them to a developer. That grounding of findings in a real system context is a meaningful architectural difference, and it shows up in the numbers. OpenAI reported that false-positive rates dropped by more than 50% across the same repositories, and noise fell by 84% since the initial rollout.
For anyone who has triaged traditional SAST output at scale, those are the numbers that matter.
How Codex Security Works
Three stages, each building on the last.
Stage 1: Threat Model Creation
Codex Security reads your repo and builds an editable, project-specific threat model of what your system does, what it trusts, and where it’s most exposed. Your team can tune it, so the agent stays aligned with your actual risk profile and builds deep context over time, unlike most SAST rules that stay frozen.
Stage 2: Vulnerability Discovery and Validation
Using that project-specific threat model as context, the agent discovers vulnerabilities and ranks findings by expected real-world impact. The important step is the next one: it pressure-tests findings through automated validation in sandboxed environments before surfacing higher-confidence findings, rather than generating a long queue of unvalidated alerts. During the private beta, it flagged 792 critical vulnerabilities and 10,561 high-severity findings across 1.2 million commits, including heap-buffer overflows, double-free bugs, authentication bypasses, and 2FA circumvention in open-source projects such as GnuTLS, OpenSSH, and Chromium. Identifying real, previously unknown critical issues in projects of that caliber is a meaningful result.
Stage 3: Remediation
For validated findings, Codex Security proposes minimal patches that respect the intent of the surrounding code. OpenAI says the fixes are generated with system context and system intent in mind, which should make them actionable fixes rather than the generic patches SAST tools have historically thrown at developers.
Where Codex Security Actually Helps
To be clear, our view is that Codex Security is a genuine improvement over the SAST status quo. It addresses a few problems the industry has long been dealing with.
The SAST noise problem
Traditional SAST tools have trained a generation of developers to ignore security alerts because a typical scan of a large codebase produces thousands of issues, most of which are low-impact. Codex Security’s automated validation is a direct response to that, and reducing false positives at this scale meaningfully improves the signal-to-noise ratio that security teams actually work with. If the 84% noise reduction holds up outside the private beta, it’s the kind of result that changes how developers engage with security tools.
Security without context-switching
Most developers don’t run security scans because the tools live outside their workflow. For teams already using Codex web through ChatGPT, Codex Security lands findings directly in the environment they use to work on code, and returns patches rather than opaque CVE descriptions. That’s a real usability improvement, and we’d rather see developers use an integrated tool like this than ignore security tooling entirely.
Deep code-level bugs
For software vulnerabilities that live entirely in source code, including buffer overflows, use-after-free errors, and certain authentication logic flaws, building deep context before flagging issues is the right approach. Identifying complex vulnerabilities in heavily reviewed open source projects like OpenSSH and Chromium demonstrates that this kind of system can find things that human review processes missed. That’s a capability the industry didn’t have two years ago.
For teams running no static analysis today, Codex Security is a significant upgrade from nothing, and we’d recommend looking at it.
What Codex Security Can’t Catch
This is the part of the story that most of the launch coverage underplayed. Codex Security reads code and validates findings in a sandboxed environment, but it does not exercise your deployed application or real production infrastructure. That sounds like a minor technical distinction until you map it against the vulnerability classes that actually cause production breaches.
Deployment and infrastructure misconfigurations
Insecure CORS policies, exposed debug modes, weak TLS configuration, reverse proxy misbehavior, cache poisoning conditions, and missing security headers. Many of these don’t exist purely in application source code, or only become visible once the system is deployed. Your code can be written correctly and still expose the entire API through a misconfigured nginx or an overly permissive CORS header. Source code analysis cannot reliably catch issues that only emerge in deployed environments.
Broken authorization at runtime
Broken Object Level Authorization (BOLA) is the number one risk on the OWASP API Security Top 10, and it remains one of the most common issues we see in customer environments. Testing whether user A can access user B’s records by manipulating an object ID requires sending authenticated requests across real identities and verifying how the server actually behaves. Code analysis can identify obviously flawed authorization logic, but it cannot confirm whether your deployed authorization holds up under real-world sessions, tokens, and infrastructure.
Business logic flaws
Can an attacker manipulate an order total by replaying a request with a modified price? Can they skip a required step in a multi-stage workflow? Can they chain two individually harmless API calls into a privilege escalation? None of those questions can be answered from the repository alone. These vulnerabilities arise from interactions between components, not from any single file.
The AI code velocity problem
A DryRun Security study tested three major AI coding agents (Codex included), building applications from scratch, and found that 87% of pull requests contained at least one software vulnerability. The most common issues were broken access control, business logic failures, OAuth implementation gaps, and WebSocket authentication holes. These aren’t edge cases. They’re precisely the vulnerability classes that other agentic tools miss, because they only surface when you test a running application. As AI coding agents accelerate the pace of shipped code, the volume of runtime-testable issues grows with it.
Where DAST Still Has to Do the Work
This is the part of the application security discussion we spend most of our time on, for obvious reasons. DAST tests the running application: real requests, real responses, real authentication flows. It’s the primary way to validate real-world exploitability for vulnerability classes that code-centric analysis cannot confirm, and it’s the approach StackHawk is built on.
Testing actual exploitability
A finding that looks exploitable in code may not be reachable in the deployed path because of routing, authentication, feature flags, or environment-specific controls. Conversely, a route that looks safe in isolation may become exploitable because of gateway behavior, proxy normalization, or deployment configuration. Code analysis can identify where to look. Runtime testing confirms what is actually reachable and exploitable.
Authorization and access control validation
Runtime security testing sends authenticated requests as different user roles to verify that your authorization boundaries hold. Can a standard user reach an admin endpoint? Can one tenant access another tenant’s data through an API that’s supposed to be scoped? These questions cannot be answered from the source code alone. They require exercising the running application.
API attack surface discovery
Source code analysis sees the endpoints defined in your code, but it can miss APIs that only exist in deployed environments or differ from what’s actually exposed in production. Source-code-based API discovery helps identify APIs that exist in your repos but are undocumented or insufficiently tested. Pairing that with runtime validation is how you map the actual live attack surface rather than the intended one.
Continuous testing in CI/CD
This is where we consistently land with customers. Modern DAST can run in CI/CD as part of pre-production testing, typically with lighter scans on each change and deeper scans at later stages. When AI agents are producing code faster than any security team can manually review it, automated runtime testing becomes a necessary backstop. A broken access control caught during a pull request doesn’t reach production.
Our Take: Use Both, Don’t Confuse Them
Codex Security versus DAST is the wrong framing. The right framing is Codex Security for code-level vulnerabilities and DAST for runtime-level vulnerabilities. They test different things, and the gaps in one are covered by the other. The mistake we’re seeing teams make right now is treating an AI code reviewer as a replacement for runtime testing. It isn’t one.
Here’s the workflow we’d recommend. Use Codex Security (or another code analysis tool) to fix vulnerabilities at the code level, including buffer overflows, injection patterns, hardcoded secrets, and similar issues during development. Then run DAST in CI/CD to validate that your authorization controls actually enforce what they claim to enforce, that your deployment configuration is secure, and that your APIs are not exposing data they shouldn’t. That includes testing for broken object-level authorization and business logic flaws that only emerge when the full application is running.
As the DryRun study we referenced earlier showed, AI coding agents introduced broken access controls and business-logic failures in 87% of pull requests. Codex Security and other agentic tools are improving at detecting some of these patterns in source code, but confirming whether any specific broken access control is actually exploitable in your deployed environment is not a code review problem. It’s a runtime problem.
Our CEO, Joni Klippert, put it directly earlier this year: “AI writes more code than your security team can review, and without automated runtime testing, those gaps ship to production unchecked.” That matches what we see in the field. Codex Security can review the code AI generates, but it cannot confirm that the authorization logic behaves correctly at runtime, that API endpoints are properly scoped in deployment, or that sensitive data isn’t leaking through an infrastructure misconfiguration.
The consensus for the Codex vs. DAST argument is this: if you’re shipping code with AI coding agents and your security story is “we run Codex Security on the repo,” there is a gap in your coverage. Codex Security is a useful tool. It is not a substitute for testing a running application. The vulnerability classes that drive the most damaging breaches, including broken access control, BOLA, and business logic flaws, still require runtime validation to confirm they are actually exploitable in your specific deployment.